Robots.txt Generator Tutorial
Learn how to use the create robots txt generator to control search engine crawlers and manage your website crawling preferences
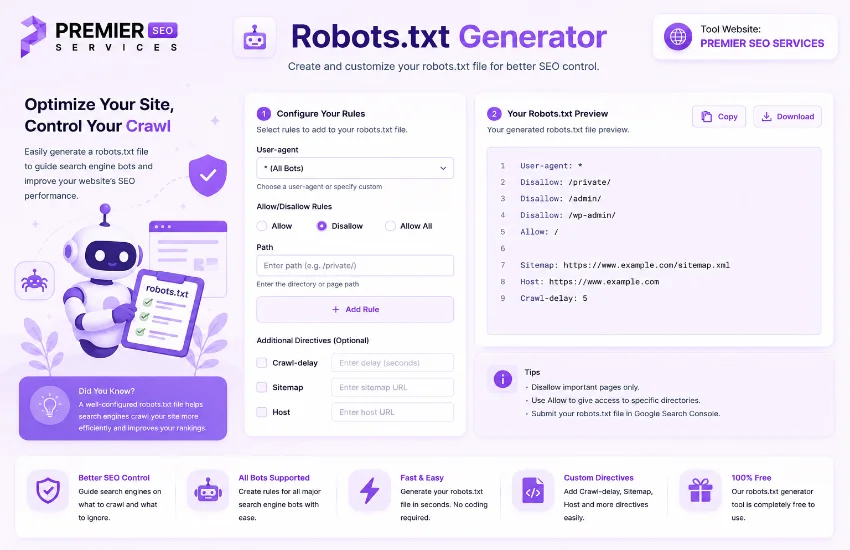
⚙ What Is a Robots.txt Generator?
A robots.txt file is one of the most essential components of any website technical SEO setup. It tells search engine bots like Googlebot, Bingbot, and others which parts of your site they are allowed to crawl and index. The Robots.txt Generator simplifies this process by providing a visual interface where you can toggle bots on and off, add custom allow and disallow rules, set crawl delays, and link your sitemap all without manually editing text files. Instead of memorizing the syntax or hunting for examples online, you get a clean panel where every option is clearly labeled and changes appear in real time in the preview area.
⚙ Managing Search Engine Bots
The first panel in the interface lists eight major search engine bots that commonly crawl websites. Each bot entry shows the bot name, the search engine it belongs to, and a toggle switch that controls whether the bot is allowed or blocked. When a toggle is on the bot appears green and active, and the generator includes an allow rule for it in the output. When a toggle is off the generator creates a Disallow rule that blocks that specific bot from crawling your entire site. Googlebot and Bingbot are enabled by default since most site owners want these two search engines indexing their pages.
⚙ Sitemap URL and Crawl Delay Settings
Below the bot selection panel you will find two additional configuration fields that add important directives to your robots.txt file. The Sitemap Location field accepts the full URL of your XML sitemap file. When you provide a sitemap URL, the generated robots.txt includes a Sitemap directive that points search engines directly to your sitemap, helping them discover all your important pages faster. The Crawl Delay field lets you specify a number of seconds that bots should wait between successive requests to your server, protecting your hosting from being overwhelmed by aggressive crawling especially on shared hosting environments.
⚙ Adding Custom Crawl Rules
The custom rule builder gives you precise control over individual crawling instructions. You specify three pieces of information for each rule. The User-Agent field determines which bot the rule applies to with the asterisk wildcard meaning all bots. The rule type selector allows you to choose between Disallow which blocks access to a specific path and Allow which explicitly permits access even when broader disallow rules exist. The Path field accepts the URL path you want to control. After filling in these fields you click Add Rule and the rule appears in a list below where you can review or delete it.
? Frequently Asked Questions
⚙ Step-by-Step Workflow
Creating a complete robots.txt file with this create robots txt generator online tool follows a logical sequence that takes you from initial configuration to final export. Each step builds on the previous one and the preview panel updates automatically so you can verify your settings at every stage.
Configure Search Engine Bots
Review the list of eight search engine bots and toggle each one on or off based on whether you want that crawler to access your site. Googlebot and Bingbot are pre-enabled for convenience. Disabled bots will be blocked with a Disallow rule.
Enter Sitemap URL and Crawl Delay
Paste your XML sitemap URL if you have one and optionally set a crawl delay to prevent bots from overwhelming your server. These fields are optional but recommended for better SEO and server performance.
Add Custom Crawling Rules
Use the custom rule panel to add specific Allow or Disallow rules for particular paths. Select the rule type, enter the path, optionally specify a User-Agent, and click Add Rule. Each added rule appears in the editable list below.
Review the Generated Output
The preview panel on the right shows your robots.txt content in real time with syntax highlighting. Verify that all your settings are reflected correctly the bot rules, custom paths, crawl delay, and sitemap URL should all appear in the correct format.
Copy or Download Your File
Use the Copy button to copy the content to your clipboard or click Download to save it as a robots.txt file. Upload the file to your website root directory using your hosting control panel or FTP client.
⚙ Understanding the Generated Output
The preview panel displays the actual robots.txt content that will be used by search engine crawlers. The output begins with a default User-agent block for all bots. If no custom rules exist for the asterisk wildcard, a Disallow with an empty path is added which means all bots are allowed to crawl everything. For each bot that is toggled on, the generator checks whether you have added custom rules specifically for that bot and generates the appropriate User-agent block. For bots that are toggled off, a Disallow rule for the entire site is generated. The sitemap URL and crawl delay are appended at the bottom of the file.
Disallow:
User-agent: Googlebot
Allow: /public/
User-agent: Bingbot
Disallow: /private-folder/
Crawl-delay: 5
Sitemap: https://example.com/sitemap.xml
⚙ Practical Applications and Use Cases
The robots.txt generator serves website owners across different scenarios. E-commerce site owners block crawlers from accessing shopping cart pages, checkout flows, and search result pages to prevent index bloat and preserve crawl budget for product pages. Bloggers and content sites block admin directories, login pages, and duplicate content sections to ensure search engines focus their crawling on actual articles. Developers testing staging or development environments use robots.txt to block all crawlers from indexing non-production content. SEO professionals create targeted rules that allow specific bots like Googlebot while blocking less useful crawlers.
⚙ Tips for Best Results
Getting the most from your robots.txt configuration requires some strategic thinking. Start by enabling only the search engines that deliver actual traffic to your site. There is no benefit to allowing every bot listed when only Google and Bing drive meaningful visitors. Use specific Disallow paths rather than broad blocking to avoid accidentally hiding important pages. Always test your robots.txt by copying the output and checking it against your site structure before uploading it to your live server. Remember that Disallow rules in robots.txt are not security measures they simply ask well-behaved bots to stay out. Anyone can still access blocked URLs directly.
For WordPress sites block access to wp-admin, wp-includes, and the /feed/ directory to keep administrative and system folders out of search results. If you run an e-commerce store, block your cart, checkout, and my-account pages to prevent duplicate content issues. For multilingual sites, ensure your sitemap URL is included in the robots.txt since it helps search engines discover translated versions of your pages. The robots.txt generator makes it easy to experiment with different configurations because the preview updates instantly as you make changes.
⚙ Behind the Generation Process
Understanding how the create robots txt generator builds your output helps you use it more effectively. When you click Generate or when any setting changes, the tool runs through a logical assembly process. It first creates the default User-agent block for all bots with an empty Disallow directive if no custom asterisk rules exist. It then iterates through each of the eight bots in the list. For enabled bots with custom rules, it creates targeted User-agent blocks with your specific Allow and Disallow paths. For disabled bots, it generates a blanket Disallow for the entire site. The sitemap URL and crawl delay are appended at the end as global directives.
The custom rules you add are stored in a temporary array in your browser memory. Each rule stores three values the target User-agent, the rule type Allow or Disallow, and the path. When you delete a rule by clicking the cross icon it is removed from this array and the generator re-runs automatically. This design means you never lose your place you can add, remove, and toggle settings freely while always seeing the current output reflected in the preview panel.
⚙ Browser Compatibility and File Upload
The create robots txt generator works across all modern browsers including Chrome, Firefox, Safari, and Edge. The entire tool runs client-side with no server communication, so your crawl settings and custom rules never leave your computer. The copy function uses the Clipboard API which works on desktop and mobile browsers. The download function generates a proper robots.txt filename that is ready for upload. Once you have downloaded your file you can upload it to your website root directory using FTP, cPanel File Manager, or your hosting providers file management tool.
For WordPress users the file goes in the root folder where your wp-config.php and wp-content folder live. For static HTML sites place it in the public_html or www directory. Make sure the filename is exactly robots.txt all lowercase with no extra characters. After uploading, test your file by visiting yourdomain.com/robots.txt in a browser. You should see the exact content you generated in the tools preview panel. Search engines typically find and check this file within a few days of it being available.
⚙ Start Using the Robots.txt Generator
Whether you are launching a new website, optimizing an existing one for better SEO, or learning how search engine crawling works, this create robots txt generator provides a complete solution for creating and managing your robots.txt file. The combination of visual bot toggles, custom rule building, sitemap integration, crawl delay settings, and real-time preview makes it suitable for beginners and advanced users alike. You do not need to remember syntax, worry about formatting errors, or search for templates. Every option is clearly labeled and the output is always valid and ready to use.
The robots.txt generator is ready whenever you are. Open the tool, configure your bots, add your rules, and generate a production-ready robots.txt file in under a minute. Your websites crawling configuration deserves the same attention you give to your content and design. This tool makes that process fast, visual, and completely error-free.